Rhetorical Analysis of Predictive LLMs
Alan Knowles
Wright State University
This assignment asks students to train a large language model (LLM) to generate Twitter posts in the style of specific accounts via a process known as few-shot learning, which trains the LLM on a small number of sample posts. Students use the trained LLM to generate tweets, then they rhetorically analyze the generated tweets. The assignment was originally developed for an entry-level Professional and Technical writing (PTW) course, but can be easily adapted to other disciplines and course levels.
Learning Goals:
- Functional literacy: Students explore what LLMs are and how they work. The choice of API can impact how much students are forced to consider the difference between words and tokens. The impact of the different training datasets on the LLM’s performance can lead to conversations about how contemporary LLMs work–via autoregressive prediction of tokens.
- Critical literacy: Students discuss potential negative ethical implications of LLMs on digital discourse. More on this in the Discussion section of the full assignment.
- Rhetorical Literacy: Students develop strategies for writing collaboratively with LLMs, they rhetorically analyze LLM-generated text, and they consider potential positive educational and professional use-cases of LLMs (e.g., how this technology can be leveraged to improve their writing).
Original Assignment Context: Intermediate level Digital Writing & Rhetoric course
Materials Needed: Accessible text generators (Hugging Face’s GPT-2 Large interface used in this assignment)
Time Frame: ~2 weeks
Introduction
When I introduce students to large language models (LLMs), I emphasize three of the technology’s most salient features: its tokenization of language, its autoregressive generation of text, and its capacity to be trained by users to perform specific tasks via few-shot learning. This assignment helps students to develop an understanding of these features while they focus on developing a broader literacy with the technology (see “Goals” section, below). As is the case with much of the discourse surrounding artificial intelligence (AI), these technical terms can be intimidating to teachers who are not steeped in LLM research. I have spoken to many teachers who have avoided incorporating LLM activities into their teaching because of this jargon barrier. The good news is, the concepts are not as complicated as they seem at first glance. Here is a brief overview.
Tokenization
Think of tokenization as the way LLMs see text – not as words or sentences, but as chunks of symbols that occur in sequence. A single token for current LLM models (e.g., GPT-3 and GPT-4) often roughly equates to one complete word, while older models (e.g., GPT-2) tend to represent words as multiple tokens, often resulting in generated text ending with partial words. The sentence in Figure 1 demonstrates how GPT-3 would tokenize it, with each token marked by a different color.

Figure 1. Tokenized Sentence
Autoregressive Text Generation
Most current LLMs are autoregressive, meaning they use a statistical model to predict the probability of tokens (output) occuring after a given sequence of tokens (input). In other words, after an LLM sees some words, it predicts which words will come next based on patterns learned in its initial training. During this initial training, the LLMs are given massive amounts of internet text and directed to learn to predict the next tokens in a sequence. This results in base LLM models that are good at a large number of text-based tasks. However, to get the most out of LLMs, users can further train them to perform very specific tasks better.
Few-shot Learning
LLMs can be trained via a process known as few-shot learning, which consists of users providing a few sample inputs and corresponding outputs of tasks they would like the LLM to complete. In other words, the user teaches the LLM what to do by demonstrating the task a few times. Following this training, the user need only provide an input and the LLM will provide an output based on patterns it deduces from the user’s training samples. This, in effect, alters the probability of occurrence the LLM ascribes to various tokens. As you will see from the assignment below, this can result in a trained LLM that imitates not only structure, but even individual voices (i.e., tone and style) from relatively few samples.
Like the AI jargon, this training process likely sounds more technically challenging than it actually is, which is one reason I believe students should encounter LLMs in the classroom. The following assignment is easily taught by inexperienced teachers (who, of course, try it once before teaching it) and completed by inexperienced students.
Overview
For this assignment, students train an LLM via few-shot learning to generate tweets in a specific style or voice by giving it a dataset of formatted sample tweets. The activity asks students to use a free online GPT-2 API (more on this in the “Materials Needed” section below). After training the LLM, students rhetorically analyze the tweets they write with the assistance of the LLM. I have used this assignment to introduce students in my college writing courses to LLMs since the spring semester of 2021. It was originally designed for an introductory-level Professional and Technical Writing (PTW) course, but I have since adapted it for use in first-year composition courses and an upper-level PTW course. The version shared here is the most general, able to be taught as a group activity in a single class period.
To prepare for this activity, a teacher must first create the two training datasets for students to use during the activity.
Creating Datasets
The first time I taught this, choosing tweets for the training data was easy. It was February 2021, just a month after the January 6 Capitol riots, and I wondered if LLMs might provide a novel way to analyze the Twitter activity of the political parties during that time. I decided to create 2 datasets of January 2021 tweets: a Donald Trump dataset and a Nancy Pelosi dataset. These datasets worked well for a few reasons:
- Important similarities: The tweets are from accounts that possess comparable rhetorical gravitas that are concerned with similar subject matter; both were leaders of their respective political parties at the time, both discussed Jan 6 events, and both offered a top-down view of American politics. This helped students focus on the rhetorical differences of generated posts, rather than on simple differences in content.
- Important differences: The rhetorical styles of the two accounts differ dramatically. As a result, depending on which dataset the LLM is trained on, it will generate content that discusses similar subject matter in very different ways.
- Important ethical insights: Political tweet datasets lead students to consider one of the most troubling ethical dilemmas created by LLMs–it requires very little effort to train them to imitate public figures and generate fake news.
I suggest teachers create datasets that adapt this activity to the content of their courses. I have taught versions of this that use datasets of tweets from individuals, organizations, and even competing hashtag campaigns. They all work well, so teachers should do what makes sense for their course. For example, a course focused on social justice rhetorics might try the activity with a #BLM dataset and an #AllLivesMatter dataset. Your choice of datasets, here, can also be a teachable moment, as deciding what tweets to include in the datasets can have important ethical implications (see question 6 in the “Discussion and Analysis” portion of the assignment for an example of this).
Formatting Datasets
After you choose the tweets to include in your two datasets, you’ll need to format them for the activity. Once formatted, students can simply copy/paste them into the chosen LLM interface and begin generating text.
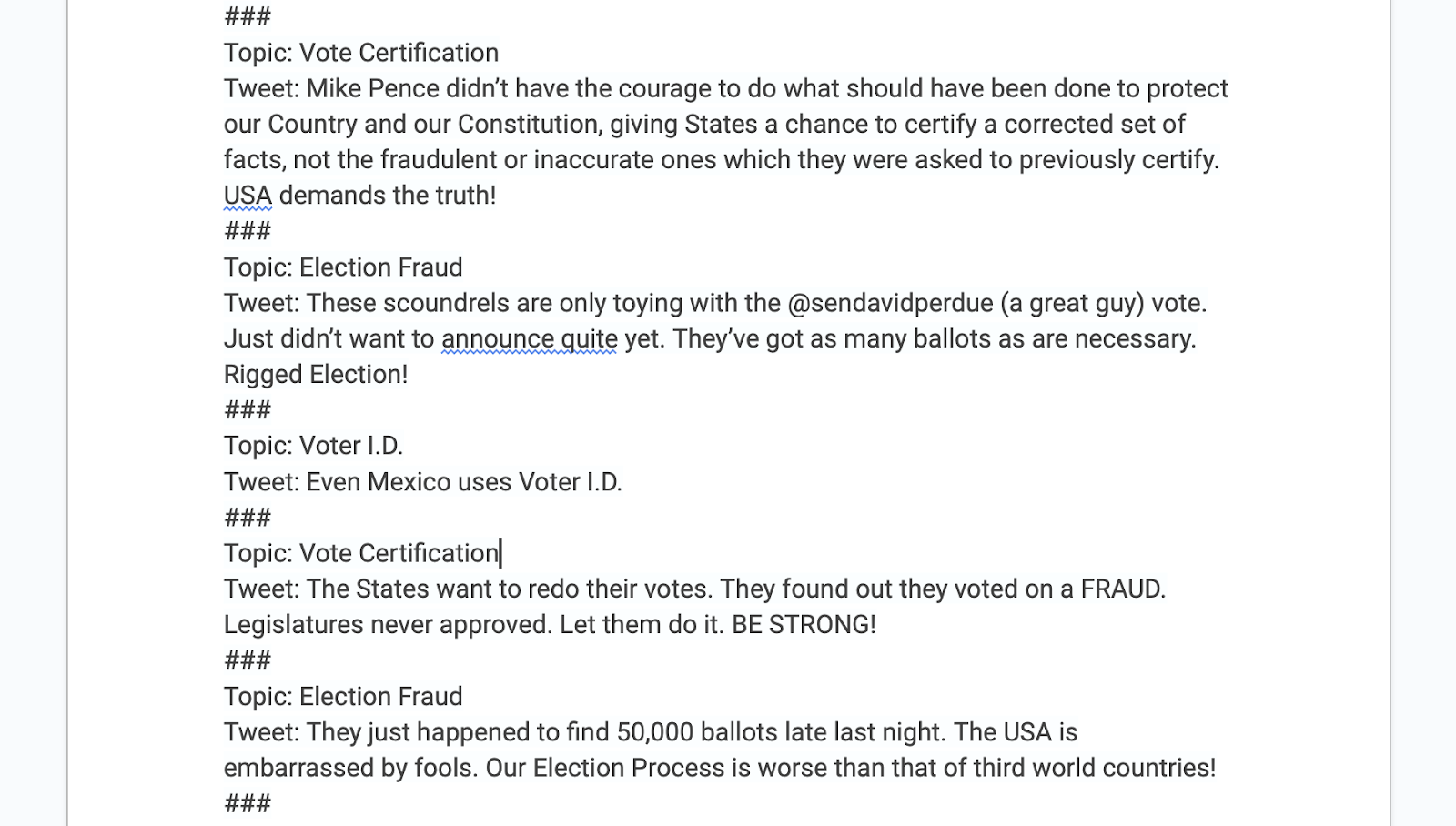
Figure 2. Screenshot of a Formatted Tweet Dataset
Note: This figure shows a small portion of the January 2021 Donald Trump dataset. The full dataset contains roughly 35 posts. The more samples, the better. You can use any word processor or text editor to format the dataset.
To format the tweets as training datasets, (1) paste them into a word processor (each dataset should be on its own document), add a topic to each tweet, then separate them by triple pound/hash signs (see Figure 2). Remember, few shot learning involves providing sample inputs/outputs to train the LLM. In this case, the outputs are copied tweets and the inputs short descriptions of the topics of those tweets. If all goes well, students will be able to provide a topic and get the LLM to generate text for tweets about that topic in the rhetorical style of the author(s) of each of the training datasets.
Goals
This activity is designed to introduce students to LLMs in a way that promotes functional, critical and rhetorical LLM literacies.
- Functional literacy: Students explore what LLMs are and how they work. The choice of API can impact how much students are forced to consider the difference between words and tokens. The impact of the different training datasets on the LLM’s performance can lead to conversations about how contemporary LLMs work–via autoregressive prediction of tokens.
- Critical literacy: Students discuss potential negative ethical implications of LLMs on digital discourse. More on this in the Discussion section of the full assignment.
- Rhetorical Literacy: Students develop strategies for writing collaboratively with LLMs, they rhetorically analyze LLM-generated text, and they consider potential positive educational and professional use-cases of LLMs (e.g., how this technology can be leveraged to improve their writing).
For my upper-level courses that cover more advanced rhetorical theory, I assign readings on multiliteracies before doing the activity. However, the activity works just as well in lower-level courses where I often do not assign these readings.
Outcomes
This activity has been largely successful each time I have taught it. Students learn to use the LLM interface quickly and are usually surprised at how well the LLM imitates the rhetorical style of the tweets in the training datasets. Some recurring outcomes:
- Students are always surprised by how impactful the training datasets are on the LLM’s output, and how well the LLM can imitate others.
- Students often note that human users have a heavy influence on what an LLM generates. This is true during the training and text generation stages. For example, in my Trump/Pelosi version of this activity, some groups get the LLM to generate standard, politically correct language with the Pelosi dataset while others use the same dataset to generate tweets more akin to political satire. Students have admitted that they steered the LLM in these directions because they preferred one politician over the other.
- Occasionally, groups will generate Trump tweets that aggressively attack Hillary Clinton, whose name never appears in the training dataset. This leads to insights about the base training process of the GPT models–the internet text they are trained on has samples of Trump attacking Clinton on Twitter and samples of the constant news coverage of those Twitter attacks. So, while the LLMs can be further trained by users, we cannot fully resolve the issues that arise from the massive text datasets used to train the base models.
Materials Needed
There are now many different LLM interfaces that students can use for this activity. For this introductory assignment, I use Hugging Face’s GPT-2 Large interface. It is a free, less-capable web interface that generates only a few tokens at a time. I find it instructive because it generates less text at once, often beginning and/or ending with partial words, which I am convinced makes students more likely to consider the important difference between words and tokens. Like many LLM interfaces, Hugging Face looks similar to a standard word processor. However, pressing the tab button at any time will prompt it to generate 3 text recommendations wherever the cursor is positioned. The length of these recommendations varies, but on average, expect 2-5 words per suggestion.
This activity can also be completed with more advanced LLMs, such as OpenAI’s GPT-3 API (known as the “Playground”). In this case, the LLM would generate entire tweets given only a topic–if you choose to do this, adjust the discussion questions accordingly.
Acknowledgments
I developed this activity for a course at Miami University (Oxford, OH) in 2021. I am grateful to the faculty mentors and members of my dissertation committee who gave me the freedom to mold what was, at the time, a new version of the Digital Writing & Rhetoric course to suit my own research interests. A sincere thank you to Jim Porter, Heidi McKee and Tim Lockridge.
The Assignment
Below is a copy of the document I give to first-year composition students for this activity. I recommend sharing this document as a Google Doc, since the cloud features help to facilitate the “Share Generated Tweets” part of the activity.
Overview
A large language model (LLM) is a type of artificial intelligence (AI) that generates natural language, or text that reads like it is human-written. Most of today’s LLMs are called autoregressive models, which means they generate natural language by predicting what text will come next given what came before. A primary feature of these language models is their ability to be further trained by users to generate specific types or styles of text. For this activity, you will practice training the GPT-2 LLM to generate tweets in the style of 2 different Twitter accounts using training datasets provided by your professor.
Use LLM to Generate Tweets
To prepare for the activity, you must first follow these steps:
- Go to the Hugging Face website (link) and choose the “GPT-2 Large” model
- Open the Trump and Pelosi January 2021 tweet datasets in separate browser tabs
- Copy/paste all of the text from one of the tweet datasets into the GPT-2 interface
- Make sure you delete the tutorial text on the Hugging Face site first
Before you start generating text, I suggest adjusting a few settings on the website. Changing the Temperature will affect how predictable the generated text is. In other words, a lower temperature will cause the LLM to generate higher probability text (more words like the, and, etc.). Raising the temperature will cause it to generate lower probability text, essentially making it more creative. Raising the Max Time setting will enable the LLM to take more time to offer suggestions, often resulting in text suggestions that contain more tokens/words. Here are my suggestions for where to start with these settings, but you are encouraged to experiment with them as you go:
- raise Temperature to 1.75
- raise Max Time to 1.5 sec
To begin generating text suggestions, press the Tab button on your computer. You can continue pressing Tab to get new suggestions until you get something you like. A few tips:
- Collaborate with the AI: tweets you generate can be entirely AI-generated or they can be a combination of AI-generated and human-written text. There is no right or wrong method.
- Interject: you can interject with your own writing anytime you like. It can be helpful to “lead” the AI by providing words for the tweet that move it in a particular direction. This can work almost like trigger words for the AI. For example, trained on Trump tweets, phrases like, “The leftists” or “The Dems” trigger the generation of predictably negative text. The Topic you provide should have a similar effect.
|
|
Share Generated Tweets
In groups, generate 3-5 tweets using both of the provided training datasets. When you are finished, copy/paste your 2 best topics/tweets from both datasets into the tables below. Make sure you paste the tweets into the correct table so we know which dataset was used to train the AI.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Discussion & Analysis
- Finding patterns: Compare the tweets you generated using the Trump dataset with the tweets your classmates generated using the Trump dataset. Are there any recurring themes, rhetorical maneuvers, stylistic choices, etc.? Do the same with the Pelosi tweets.
- Comparative analysis: How different were the tweets generated using the Trump data from those generated using the Pelosi data? Did you try to use the same topics for both datasets? What might differences/similarities, here, suggest about the tweets included in the training datasets? What might they suggest about the way the LLM works?
- Augmented Analysis: Do you think using the LLM in this way gave you any insights into the rhetorical strategies of these two politicians that you wouldn't have had otherwise? What about doing this type of LLM analysis on much larger datasets (e.g., one that includes tweets from all Republican congress members, and another for the Democrats)? Might this ability of the LLM to discern and replicate rhetorical patterns be more useful for analyzing larger text datasets?
- Unexpected results: Are there any instances of generated tweets not resembling the training data? Did any of the generated tweets surprise you?
- Human bias: How much do you think you influenced the generated tweets? Did you lead the AI to generate more positive/negative tweets for either politician? How much did your own interjections of text impact this? Did this have anything to do with your own political leanings?
- Ethical concerns: What are the ethical implications of being able to imitate political figures so easily with AI? Were your generated tweets convincing enough to pass as coming from the real politician? How likely do you think it is that bad actors will publish such content?
- Other: Did you have trouble generating tweets that sounded like Trump or Pelosi? Did you have more trouble with one than the other? Why might this be?